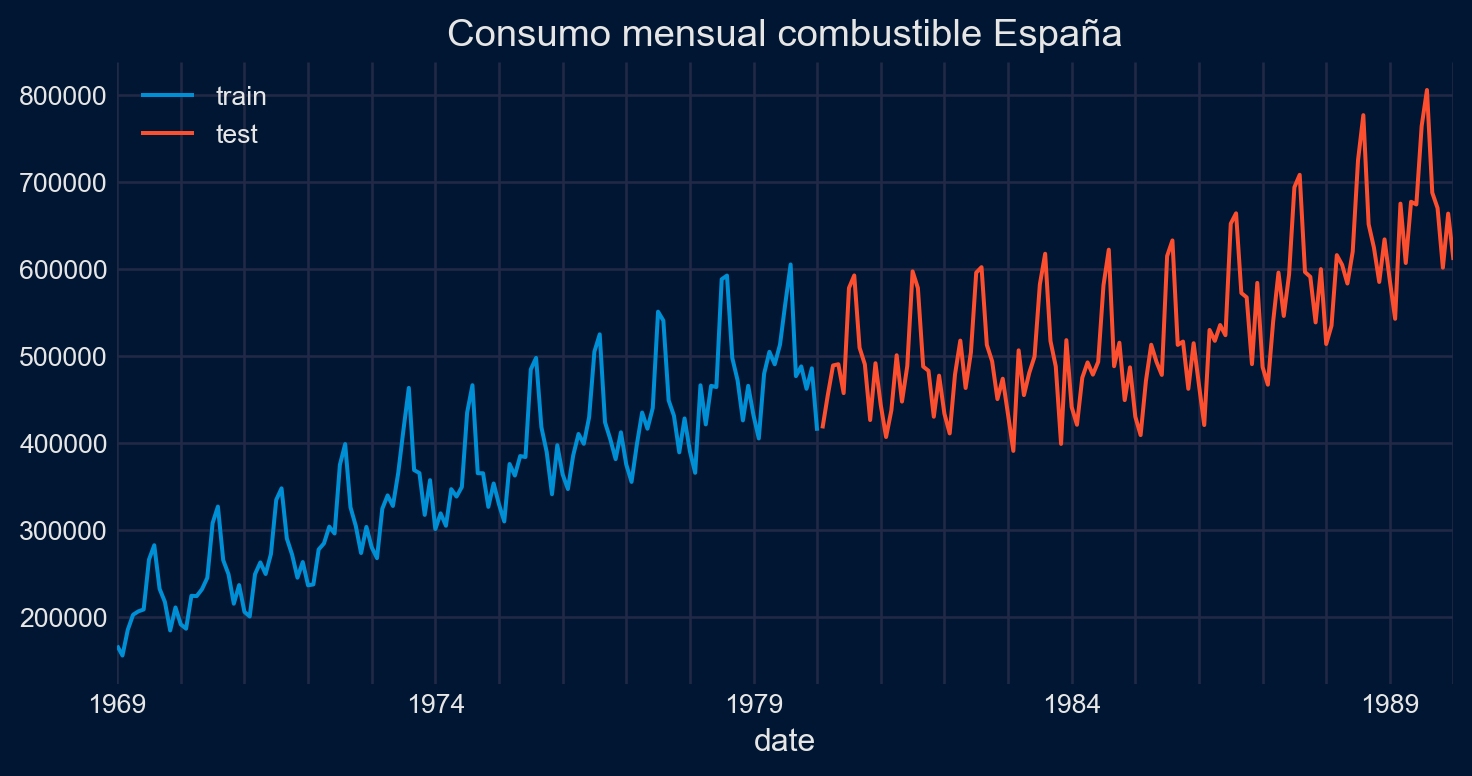
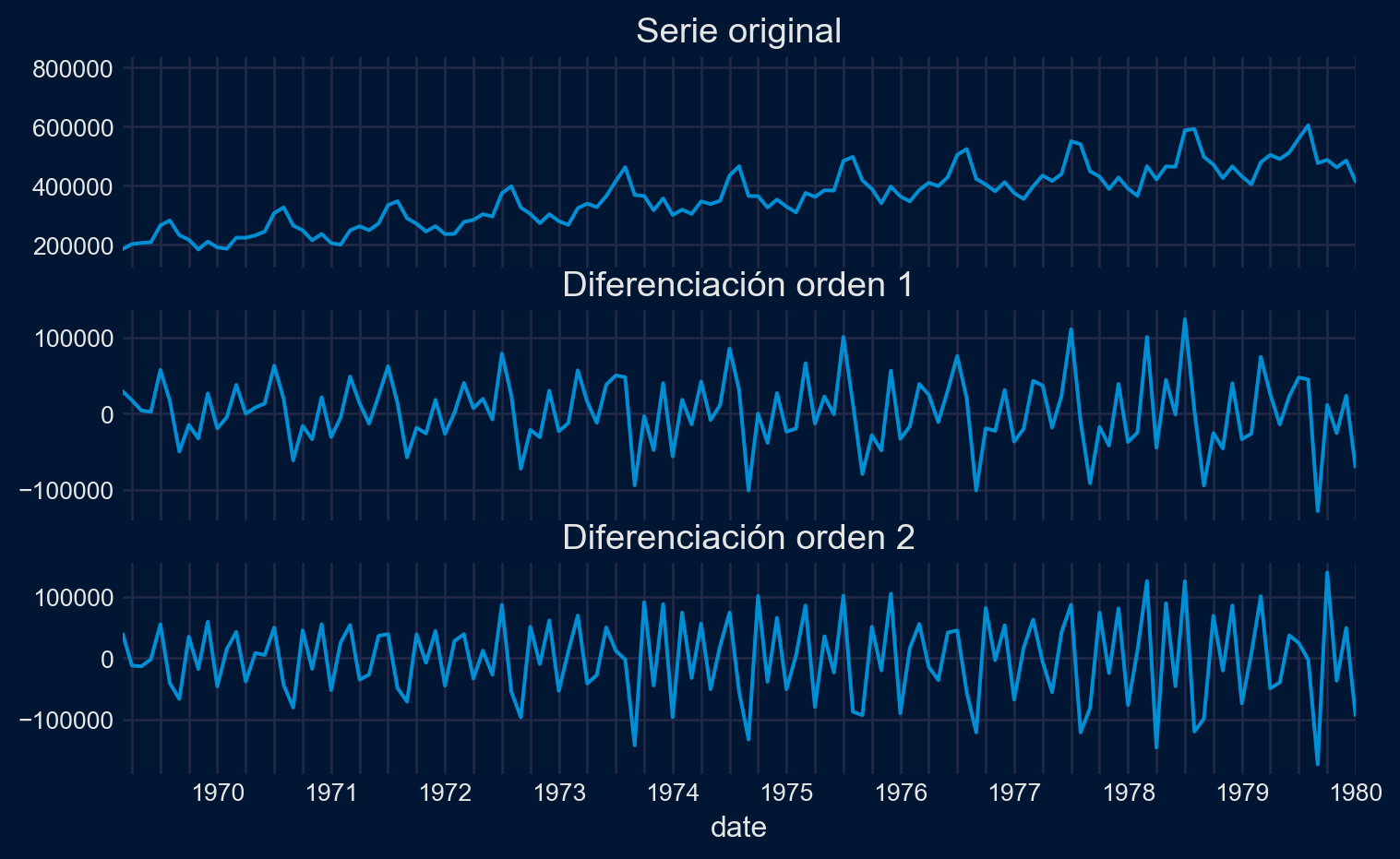
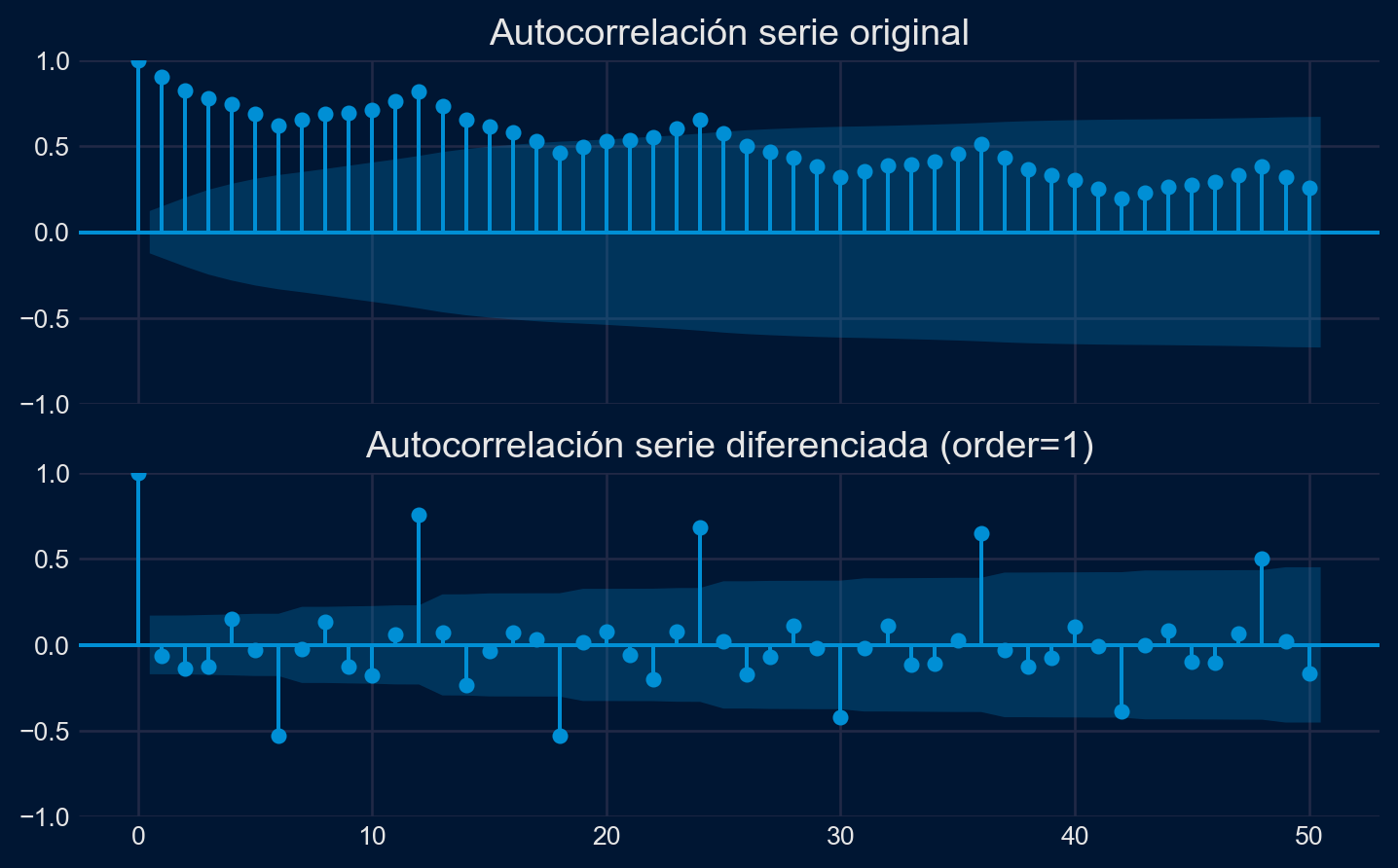
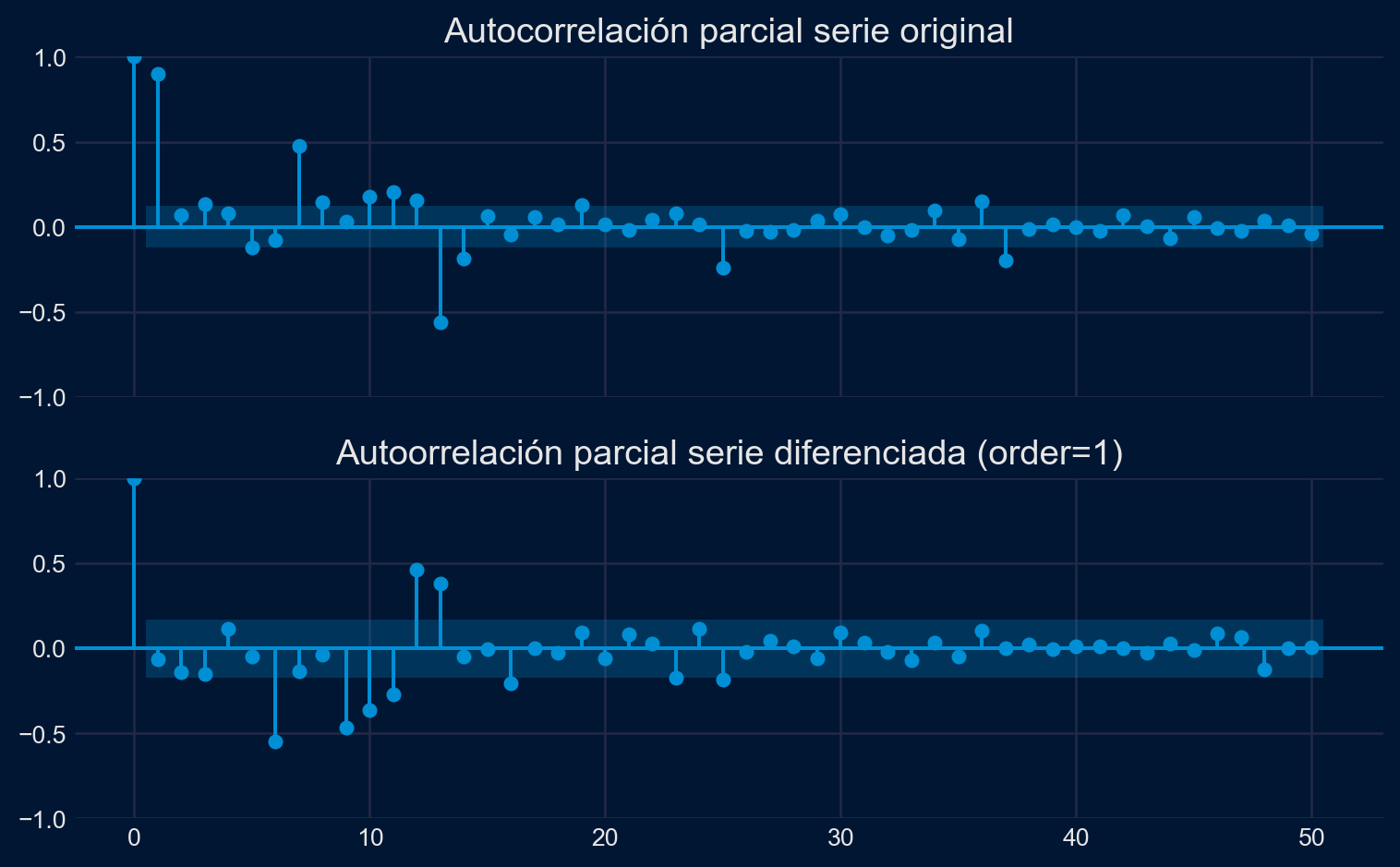
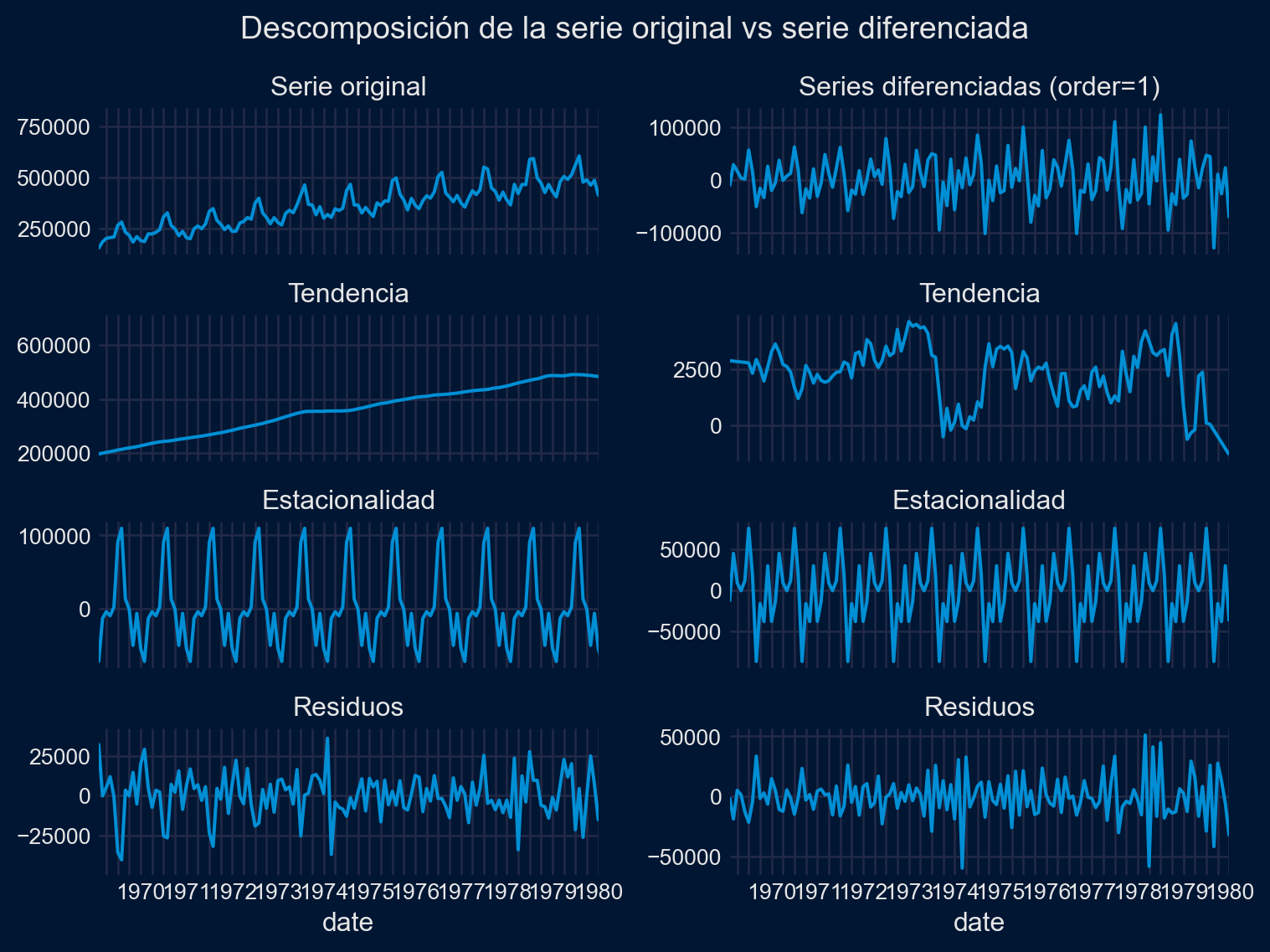
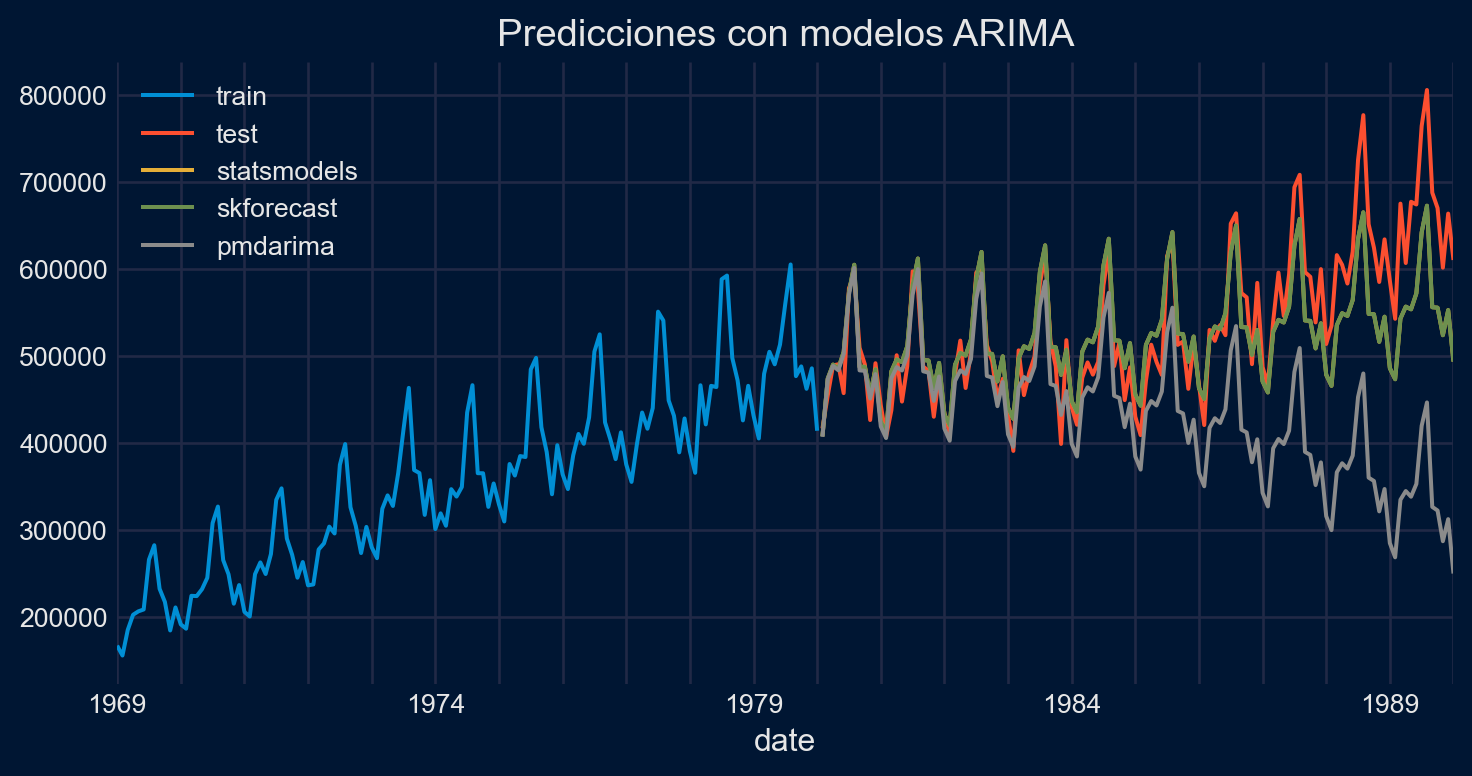
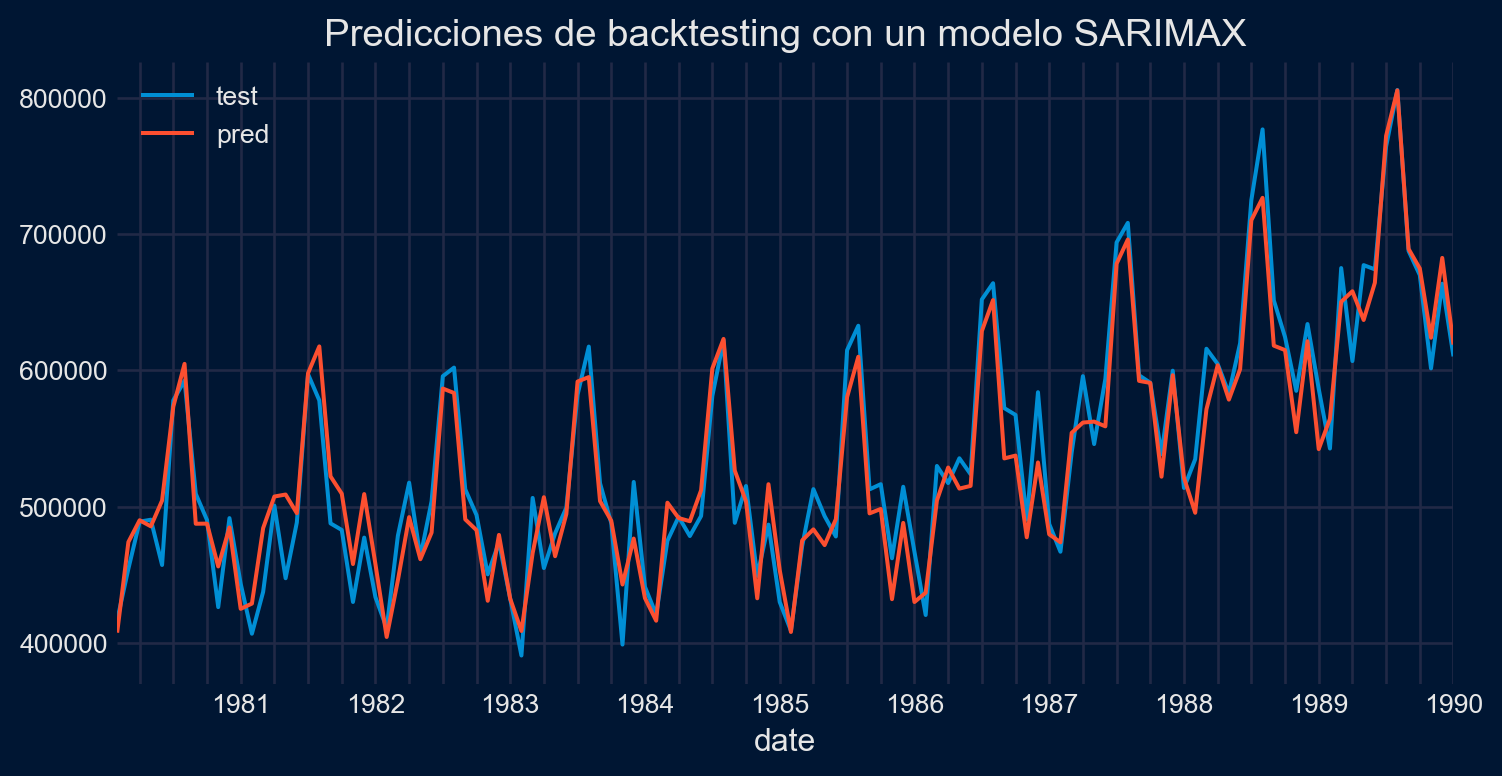
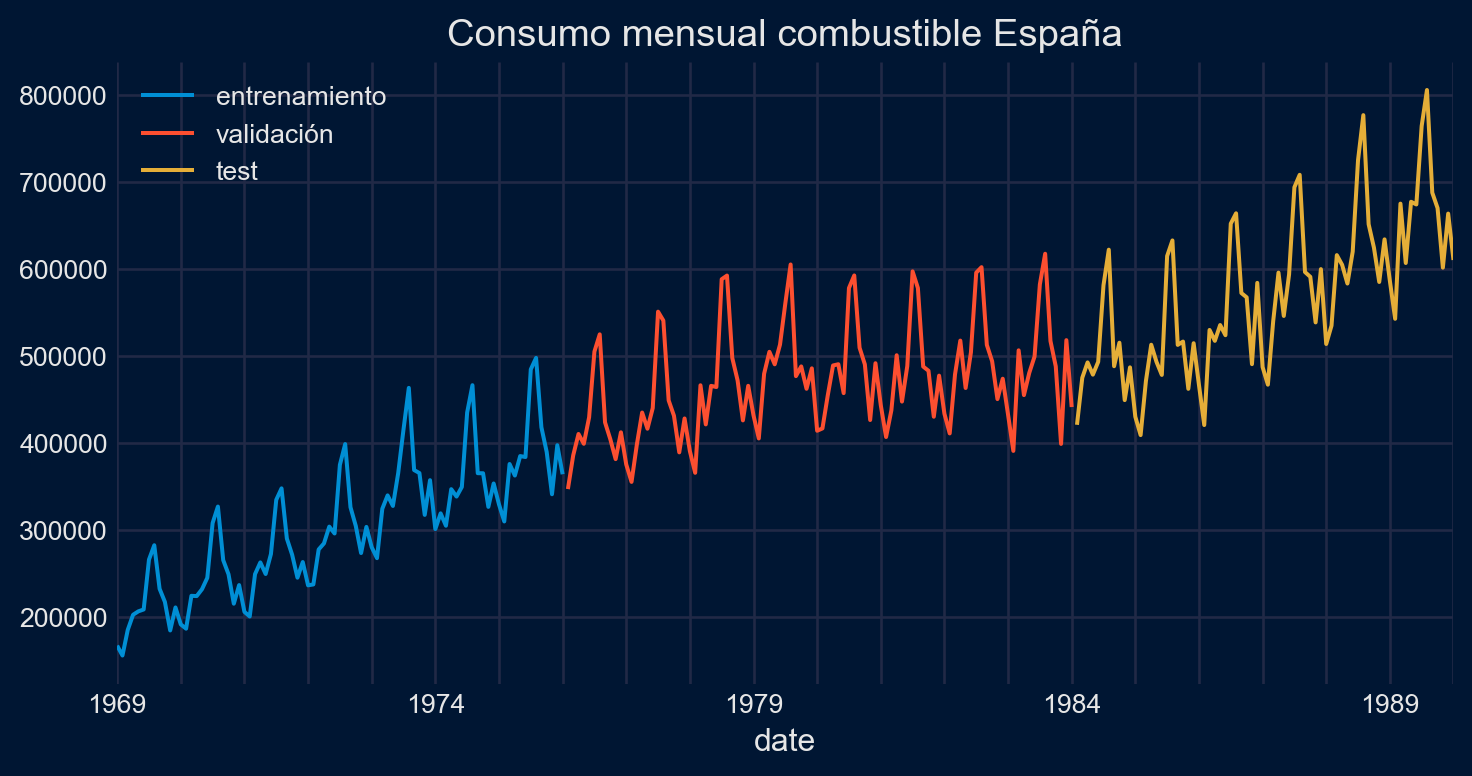
Performing stepwise search to minimize aic
ARIMA(0,1,0)(1,1,1)[12] : AIC=3903.204, Time=0.07 sec
ARIMA(0,1,0)(0,1,0)[12] : AIC=3942.897, Time=0.01 sec
ARIMA(1,1,0)(1,1,0)[12] : AIC=3846.786, Time=0.06 sec
ARIMA(0,1,1)(0,1,1)[12] : AIC=3840.318, Time=0.09 sec
ARIMA(0,1,1)(0,1,0)[12] : AIC=3873.797, Time=0.03 sec
ARIMA(0,1,1)(1,1,1)[12] : AIC=3841.882, Time=0.13 sec
ARIMA(0,1,1)(0,1,2)[12] : AIC=3841.572, Time=0.69 sec
ARIMA(0,1,1)(1,1,0)[12] : AIC=3852.231, Time=0.09 sec
ARIMA(0,1,1)(1,1,2)[12] : AIC=3842.593, Time=1.04 sec
ARIMA(0,1,0)(0,1,1)[12] : AIC=3904.615, Time=0.05 sec
ARIMA(1,1,1)(0,1,1)[12] : AIC=3834.135, Time=0.14 sec
ARIMA(1,1,1)(0,1,0)[12] : AIC=3866.187, Time=0.03 sec
ARIMA(1,1,1)(1,1,1)[12] : AIC=3835.564, Time=0.14 sec
ARIMA(1,1,1)(0,1,2)[12] : AIC=3835.160, Time=0.71 sec
ARIMA(1,1,1)(1,1,0)[12] : AIC=3844.410, Time=0.09 sec
ARIMA(1,1,1)(1,1,2)[12] : AIC=3836.443, Time=1.10 sec
ARIMA(1,1,0)(0,1,1)[12] : AIC=3836.696, Time=0.08 sec
ARIMA(2,1,1)(0,1,1)[12] : AIC=3836.104, Time=0.30 sec
ARIMA(1,1,2)(0,1,1)[12] : AIC=3836.107, Time=0.21 sec
ARIMA(0,1,2)(0,1,1)[12] : AIC=3834.320, Time=0.12 sec
ARIMA(2,1,0)(0,1,1)[12] : AIC=3834.277, Time=0.11 sec
ARIMA(2,1,2)(0,1,1)[12] : AIC=3837.435, Time=0.35 sec
ARIMA(1,1,1)(0,1,1)[12] intercept : AIC=3835.455, Time=0.15 sec
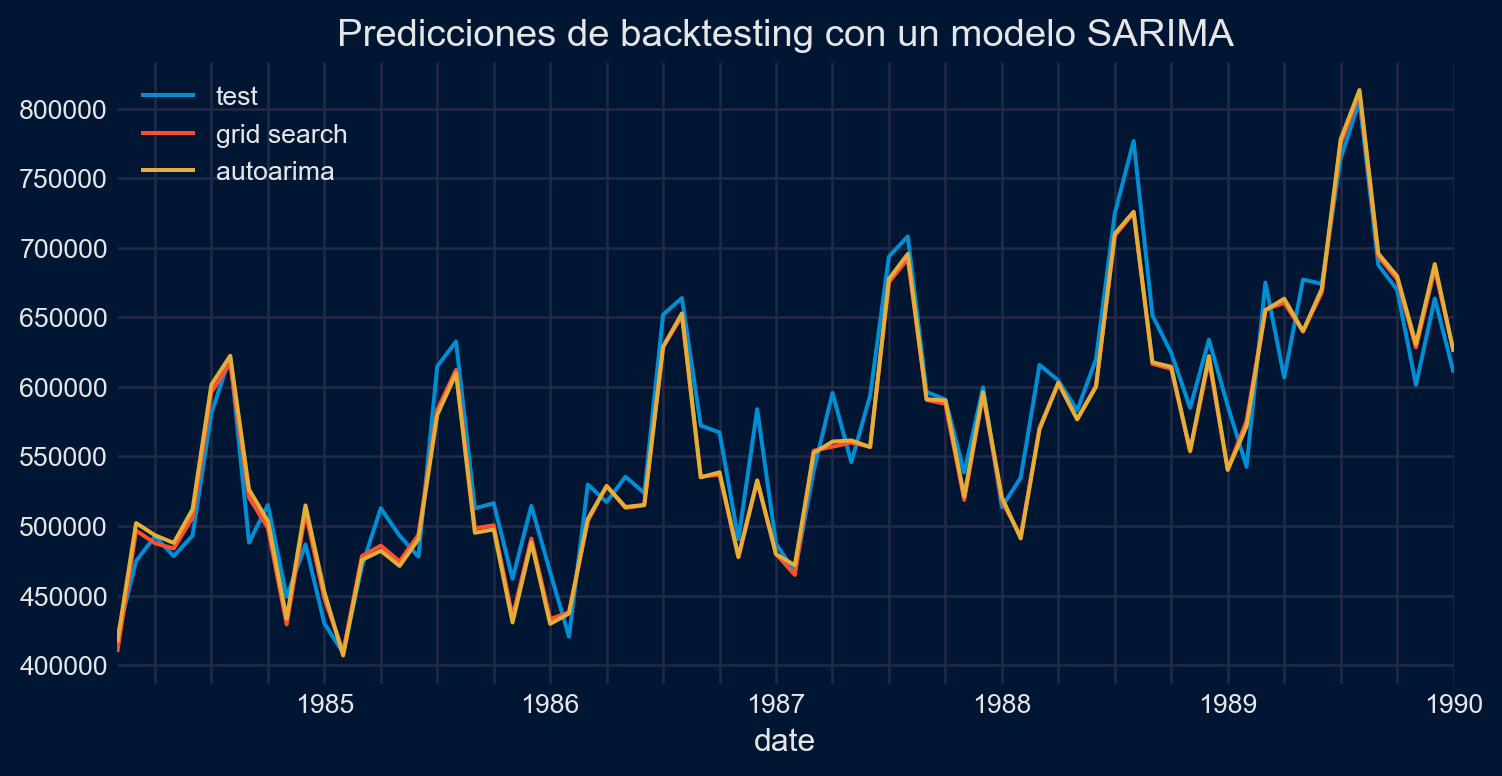
Best model: ARIMA(1,1,1)(0,1,1)[12]
Total fit time: 5.804 seconds